在近年来人工智能的发展浪潮中,大模型的崛起引领了自然语言处理、计算机视觉等多个领域的创新与突破。随着各种大型预训练模型的出现,研究者和企业也逐渐将目光投向了模型的性能排名与创新能力。本文将围绕“DeepSeek大模型排名一览”进行详细介绍,帮助读者了解当前行业内最具代表性与前沿性的模型现状与发展趋势。
首先,什么是大模型?简单来说,大模型是指参数规模庞大的深度学习模型,通常参数数量达到数十亿甚至上百亿级别。这些模型通过海量的数据训练,具备了更强的理解与生成能力,能够在多种任务中表现出色。从自然语言理解到生成,从多模态融合到自主学习,大模型正逐渐成为人工智能研究的核心驱动力。
在“DeepSeek大模型排名一览”中,我们可以看到多个知名模型各自的性能表现和技术特色。例如,OpenAI的GPT系列一直是行业的标杆。尤其是GPT-4,它在多项自然语言处理任务中展现出了超凡的能力,成为目前公认的旗舰级模型之一。其大规模参数和深层次的训练策略,使其在文本生成、问答系统、语言理解等方面的表现都达到了新高度。
除了OpenAI,谷歌的BERT和其衍生版本也占据重要位置。BERT模型通过双向编码器结构,极大提升了句子理解能力,成为搜索引擎和文本分类中的基础模型。而随后推出的T5和PaLM系列,进一步扩展了模型的应用场景和性能边界,特别是在多任务学习和多模态融合方面展现出强大的潜力。

此外,Facebook AI Research(FAIR)推出的模型如RoBERTa、OPT等,也在性能评比中表现亮眼。RoBERTa在BERT的基础上进行了优化,通过调整训练策略,提升了模型的泛化能力。而OPT模型以开源和规模多样化的特点,促进了学术界和工业界的广泛应用与研究。
在多模态方面,OpenAI的GPT-4和DeepMind的Gato等模型开始表现出跨模态处理能力。它们不仅能理解文本,还能处理图像、声音等多种数据形式,推动了AI在机器人、虚拟助手等领域的应用落地。这类多模态模型的出现,代表了大模型发展中的一大趋势:向智能更全面、更融合的方向演进。
在排名方法方面,评测标准多样,包括但不限于LAMBADA、SuperGLUE等自然语言理解基准,以及模型参数数量、训练数据规模、推理速度等指标。同时,行业内也在不断探索结合模型的创新能力、泛化能力与偏差问题的综合评估体系。这一系列指标共同构建了“DeepSeek大模型排名”的科学依据,为研究者提供了比较模型性能的参考依据。
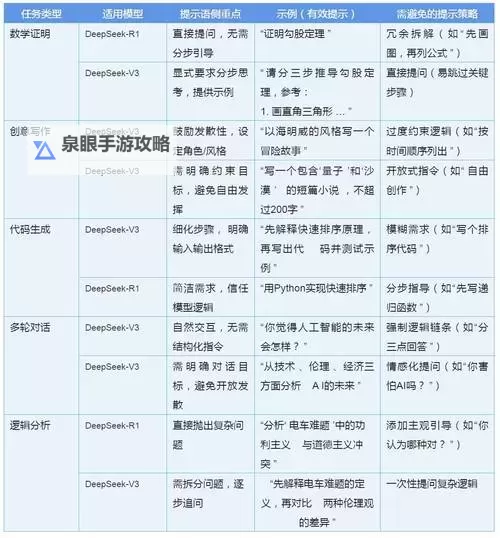
当然,排名只是反映模型某一时点的性能表现。未来,随着新技术的不断涌现和模型规模的持续扩大,排行榜也会不断变化。很多研究者开始关注模型的实用性、可解释性、能耗效率等多维度指标,以实现更全面、科学的评估体系。特别是在AI伦理与可持续发展的背景下,模型的节能、透明和公平性也逐渐成为重要考量因素。
总结来说,“DeepSeek大模型排名一览”不仅是对当前人工智能行业研究成果的总结,更是展望未来发展的方向。大模型的不断演进,将推动AI在更多领域实现深层次的变革:从科技创新到社会应用,从工业制造到日常生活,人工智能的触角正逐步深入每个角落。未来,随着技术的不断突破和应用的拓展,期待大模型带来更多令人振奋的创新与可能性。